The master algorithm by Pedro Domingos
How the quest for the ultimate learning machine will remake our world
[ I love this book by its overwhelming insights into the future than can be]
The central hypothesis of this book: All knowledge -past, present, and future- can be derived from data by a single, universal learning algorithm.
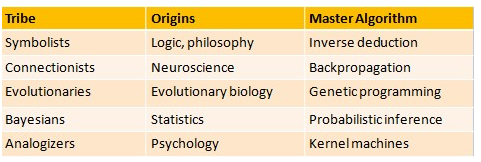
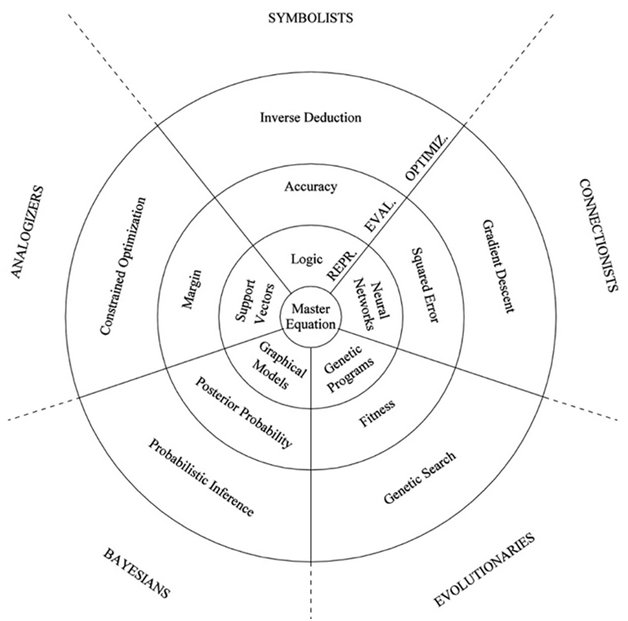
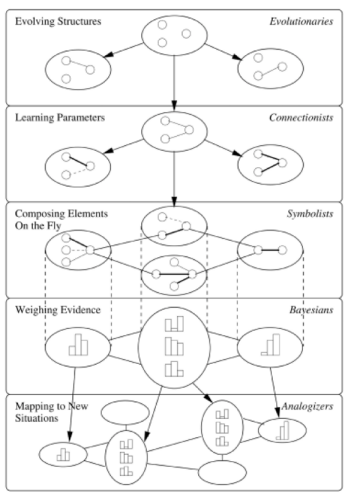
Symbolists view learning as the inverse of deduction and take ideas from philosophy, psychology and logic. Connectionists reverse engineer the brain and are inspired by neuroscience and physics. Evolutionaries simulate evolution on the computer and draw on genetics and evolutionary biology. Bayesians believe learning is a form of probabilistic inference and have their roots in statistics. Analyzers learn by extrapolating from similarity judgments and are influenced by psychology and mathematical optimization.
Each of the above five tribes of machine learning has its own master algorithms, a general purpose learner that you can in principle use to discover knowledge from data in any domain. The symbolists’ master algorithm is inverse deduction, the connectionists’ is backpropagation, the evolutionaries’ is generic programming, the Bayesians’ is Bayesian inference, and analyzers’ is the support vector machine. If exists, the Master algorithm can derive all knowledge in the world - past, present and future - from data.
The Machine-learning Revolution.
Claude Shannon better known as the father of information theory, was the first to realize that what transistors are doing, as they switch on and off in response to other transistors, is reasoning Symbol algorithms can be represented by diagrams:AND, OR, NOT operations.
Algorithms are an exacting standard. It’s often said that you don’t really understand something until you can express it as an algorithm. For example, Newton’s second law, arguably the most important equation of all time, tells you to compute the net force on an object by multiplying its mass by its acceleration. It also tells you implicitly that the acceleration is the force divided by the mass, but making that explicit is itself an algorithmic step.
There is a serpent in this Eden. It’s called the complexity monster. Like the Hydra, the complexity monster has many heads. One of them is space complexity: the number of bits of information an algorithm needs to store in the computer’s memory. If the algorithm needs more memory than the computer can provide, it is useless and must be discarded. Then there is the evil sister, time complexity: how long the algorithm takes to run, that is, how many steps of using and reusing the transistors it has to go through before it produces the desired results. If it is longer than we can wait, the algorithm is again useless. But the scariest face of the complexity monster is human complexity. When algorithms become too intricate for our poor human brains to understand, when the interactions between different parts of the algorithm are too many and too involved, errors creep in, we can't find them and fix them, and the algorithm doesn’t do want we want.
Learning algorithm are seeds, data is soil, and the learned programs are the grown plants. The machine-learning expert is like a farmer, sowing the seeds, irrigating and fertilizing the soil, and keeping an eye on the health of the crop but otherwise staying out of the way.
We can think of machine learning as the inverse of programming,, in the same way that the square root is the inverse of the square or integration is the inverse of differentiation.
In the information-processing ecosystem, learners are the superpredators. Database, crawlers, indexers and so on are the herbivores, patiently mugging on endless fields of data. Statistical algorithms, online analytics processing and so are the predators.
Machine-learning experts are an elite priesthood even among computer scientists. This is because computer scientists particularly those of an older generation, don’t understand machine learning. This is because computer science has traditionally been all about thinking deterministically, but machine learning requires thinking statistically.
The industrial revolution automated manual work and the information revolution did the same for mental work, but machine learning automated automation itself. Without it, programmers become the bottleneck holding up the progress. With it, the pace of progress picks up.
Both Google and Yahoo use auctions to sell ads and machine learning to predict how likely a user is to click on an ad. Google’s learning algorithms are much better than Yahoo’s. This is not the only reason for the difference in their market caps, but it is a big one. Every predicted click that doesn't happen is a wasted opportunity for the advertiser and lost revenue for the website.
Once the inevitable happens and learning algorithms become the middlemen, power becomes concentrated in them. Google algorithms largely determine what information you find. Amazon’s what products you buy etc. The last mile is still yours - choosing from among the options the algorithms present you with - but 99.(% percent of the selection was done by them.
Data is the new ‘oil’ is a popular refrain and as with oil, refining it is big business.
Machine learning automates discovery. It is no surprise, then, that it is revolutionizing science as much as it’s revolutionizing business. To make a progress, every field of science needs to have data commensurate with the complexity of the phenomena it studies. This is why physics was the first science to take off: Tycho Brahe's recordings of the positions of the planets and Galileo’s observations of pendulums and inclined planes were enough to infer Newton’s laws. It is also why molecular biology despite being younger than neuroscience has outpaced it: DNA microarrays and high-throughput sequencing provide a volume of data that neuroscientists can only hope for. And it is the reason why social science research is such an uphill battle.
With big data and machine learning, you can understand much more complex phenomena than before. In most fields, scientists have traditionally used only very limited kind of models, like linear regression. Unfortunately most phenomena in the world are nonlinear.
Bill Gates remark that a breakthrough in machine learning would be worth ten Microsoft will seem conservative. Machine learning will bring about not just a new era of civilization, but a new stage in the evolution of life on Earth.
The Master Algorithm
Just a few algorithms are responsible for the great majority of machine-learning applications. Naive Bayes, a learning algorithm that can be expressed as a single short equation. Given a database of patient records, Naive Bayes can learn to diagnose the condition in a fraction of a second, often better than doctors who spent many years in medical school.
Nearest-neighbor algorithm has been used for everything from handwriting recognition to controlling robot hands to recommending books and movies you might like.
Decision tree learners are equally apt at deciding whether your credit card application should be accepted, finding splice junctions in DNA, and choosing the next move in a game of chess.
In physics, the same equation applied to different quantities often describe phenomena in completely different fields: The wave equation the diffusion equation, the Poisson's’ equation. Quite conceivably, they are all instances of a master equation and all the Master Algorithm needs to do is figure out how to instantiate it for different data sets.
Physics is unique in its simplicity. Outside physics and engineering, the track record of mathematics is more mixed. Biology and sociology will never be as simple as physics, but the method by which we discover their truths can be.
Bayes theorem is a machine that turns data into knowledge. According to Bayesian statisticians, it is the only correct way to turn data into knowledge.
P and NP are the two most important classes of problems in computer science.
Stories of falling apples notwithstanding, deep scientific truths are not low-hanging fruit. Science goes through three phases, which we can call the Brahe, Kepler, and Newton phases. Brahe phase, we gather lots of data, In Kepler phase, we fit empirical laws to the data. In Newton’s phase, we discover the deeper truths. Most science consists of Brahe and Kepler like work; Newton moments are rare. Today, big data does the work of billions of Brahs and machine learning the work of millions of Kepler's. If there are more Newton moments to be had, they are a likely to come from tomorrow's learning algorithms as from tomorrow’s even more overwhelmed scientist or at least from a combination of the two.
The power of theory lies in how much it simplifies our description of the world. Armed with Newton’s laws, we only need to know the masses, positions and velocities of all objects at one point in the time,; their positions and velocities at all times follow. So Newton’s laws reduce our description of the world by a factor of the number of distinguishable instants in the history of universe, past and future.
Newton’s laws are only an approximation of the true laws of physics, so let's replace them with a string theory, ignoring all its problem and the question of whether it can never be empirically validated.
First problem is In reality we never have enough data to completely determine the world. Second problem is that even if we had complete knowledge of the world at some point in time, the laws of physics would still not allow us to determine its past and future. The theories we have in biology, psychology, sociology or economics are not corollaries of the laws of physics; they had to be created from scratch.
Hume’s problem of induction
Rationalists believe that the senses deceive and that logical reasoning is the only sure path to knowledge. Empiricists believe that all reasoning is fallible and that knowledge must come from observation and experimentation. The French are rationalists; the Anglo-Saxon are empiricists.
The rationalists like to plan everything in advance before making the first move. The empiricist prefers to try things and see how they turn out. Plato was an early rationalist and Aristotle an early empiricist.
Newton’s third rule: Whatever is true of everything we have seen is true of everything in the universe.
Harvard’s Leslie Valiant received the Turing Award, the Nobel price of computer science, for inventing the type analysis which he describes in his book entitled, approximately enough, “Probably Approximately Correct’
How does your brain learn
Donald Hebb, a Canadian psychologist, stated that “Neurons that fire together wire together”. A neural network is more like a social network, where a few close friends count for more than thousands of Facebook ones. And it’s the friends you trust most that influence you the most.
The curve which looks like an elongated S is variously known as the logistic, sigmoid or S curve. Peruse it closely, because it is the most important curve in the world. At first the output increases slowly with the input, so slowly it seems constant. The it starts to change faster, they very fast, then slower and slower until it becomes almost constant again. Joseph Schumpeter said that the economy evolves by cracks and leaps.: S curve are the shape of creative destruction. Every motion of your muscles follow an S curve; slow, then fast , then slow again. The S curve is not just important as a model in its own right; it is also the hack of all trades of mathematics. Many phenomena we think of as linear are in fact S curve, because nothing can grow without limit. When someone talks about exponential growth, ask yourself: How soon will it turn into an S curve? In fact, every function can be closely approximated by a sum of S curves.
The path to optimal learning begins with a formula that many people have heard of: Bayes’ theorem: simple rule for updating your degree of belief in a hypothesis when you receive new evidence.
Christianity as we know it was invented by Saint Paul, while Jesus saw himself as the pinnacle of the Jewish faith. Similarly, Bayesianism as we know it was invented by Pierre-Simon de Laplace, a Frenchman who was born five decades after Bayes. Bayes was the preacher who first described a new way to think about chance, but it was Laplace who codified those insights into the theorem that bears Bayes’ name. This is ironic, since LaPlace was also the father of probability theory. Which he believed was just common sense reduced to calculation
As the statistician George Box famously put it: “All models are wrong, but some are useful”. An oversimplified model that you have enough data to estimate is better than a perfect one that you don’t. The economist Milton Friedman even argued in a highly influential essay that the best theories are the most simplified, provided their predictions are accurate, because they explain the most with the least. .
Analogical reasoning has a distinguished intellectual pedigree. Aristotle expressed it in his law of similarity.: if two things are similar, the thought of one will tend to trigger the thought of the other. William James believed that “ this sense of sameness is the very keel and backbone of our thinking”. Some contemporary psychologists even argue that human cognition in its entirely is a fabric of analogies.
Nearest-neighbor is the simplest and fastest learning algorithms ever invented. In fact, you could even say it is the fastest algorithm of any kind that could ever be invented. It consists of doing exactly nothing, and therefore takes zero time to run.
Help-desk are currently the most popular applications of case-based reasoning. Most still employ a human intermediary, but IPSoft Eliza talks directly to the customer. Eliza , who comes complete with a 3D interactive video persona, has solved over 20 million customer problems to date, mostly for blue-chip US companies. “Greetings from Robotistan, outsourcing’s cheapest new destination”. And just as outsourcing keeps climbing the skills ladder, so does analogical learning. The first robo-lawyers that argue for a particular verdict based on precedents have already been built. One such system correctly predicted the outcomes of over 90 % of the trade secret cases it examined.
Arguably even higher up in the skills ladder in music composition. David Cope, an emeritus professor of music at the University of California, Santa Cruz, designed an algorithm that creates new music in the style of famous composers by selecting and recombining short passages from their work. At a conference I attended some years ago, he played three Mozart pieces: one by the real Mozart, one by a human composer imitating Mozart and one by his system. He then asked the audience to vote for the authentic Amadeus. Wolfgang won, but the computer beat the human imitator. If Cope is right, creativity - the ultimate unfathomable - boils down to analogy and recombination.
Analyzers neatest trick, however, is learning across problem domains. Humans do it all the time. Wall Street hires lots of physicists because physical and financial problems, although superficially very different, often have a similar mathematical structure. Yet all the learners we have seen so far would fall flat, if we say trained them to predict Brownian motion and then asked them to predict the stock market.
Principal component analysis (PCA) as this process is known is one of the key tools in the scientist's toolkit. Psychologists have found that personality boils down to five dimensions - extraversion, agreeableness, conscientiousness, neuroticism and openness to experience- which they can infer from your tweets and blog posts. Applying PCA to congressional votes and poll data shows that, contrary to popular belief, politics is not mainly about liberals versus conservatives. rather , people differ along two main dimensions: one for economic issues and one for social ones.
Research on reinforcement learning started in earnest in the early 1980s. Reinforcement learning with neural networks has had some notable successes. An early one was a human-level backgammon player. More recently, a reinforcement learner from DeepMind, a London based startup, beat an expert human player at Pong and other simple arcade games. It used a deep network to predict actions values from the console screen’s raw pixels. With its end-to-end vision, learning, and control, the system bore at least a passing resemblance to an artificial brain. This may help explain why Google paid half a billion dollars for deepMind, a company with ni products, no revenues and few employees.
In 1979, Allen Newell and Paul Rosenbloom started wondering what could be the reason for this so-called power law of practice. We perceive and remember things in chunks and we can only hold so many chunks in short-term memory at any given time (seven plus or minus two, according to the classic paper by George Miller). Crucially, grouping things into chunks allows us to process much more information that we otherwise could. That is why telephone numbers have hyphens:1-723-458-3897 is much easier to remember than 172344563897. Herbert Simon, AI cofounder, had earlier found that the main difference between novice and expert chess players is that novices perceive chess positions one piece at a time, while experts see larger patterns involving multiple pieces. Getting better at chess mainly involves acquiring more and larger such chunks.
Chunking and reinforcement learning are not as widely used in business as supervised learning, clustering or dimensionality reduction , but a simple type of learning by interacting with the environment is: learning the effects of your actions.
Many people worry that human-directed evolution will permanently split the human race into a class of genetic haves and one of have-nots. This strikes me as a single failure of imagination. Natural evolution did not result in just two species, one subservient to the other, but in an infinite variety of creatures and intricate ecosystems. Why would artificial evolution, building on it but less constrained, do so?
Site: alchemy.cs.washington.edu
1 comment:
Well, add more information and inform us about the most common problems. The professional creator for online class mentor com is the best writing service. But I want to say that the visual information is perfect.
Post a Comment